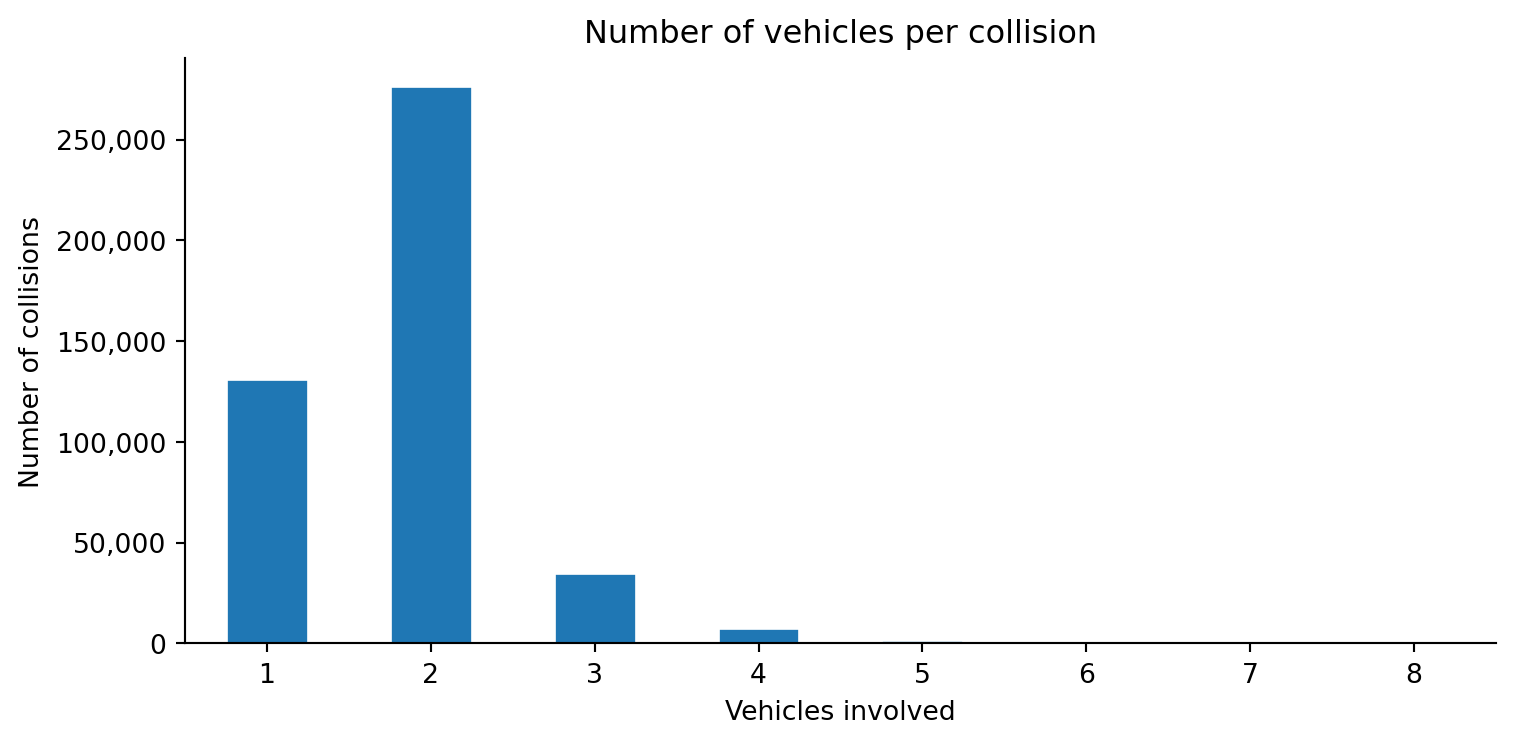
Source notes for STATS19 police-reported injury collision data, including coverage, fields, filtering, and use in collision modelling.
1 Why this matters
Important
STATS19 is the outcome variable for this project. Every collision used to train and evaluate the risk model comes from this dataset. Its coverage, reporting biases, and severity classification directly shape what the model can and cannot learn.
Most road safety work in Great Britain is built on STATS19 because it is the only national, geocoded, severity-coded collision dataset. But it only records collisions that (a) involved personal injury and (b) were reported to the police. What it misses is as important as what it includes.
2 What this page answers
What is STATS19 and what does it contain?
How is the data collected, and what biases does that introduce?
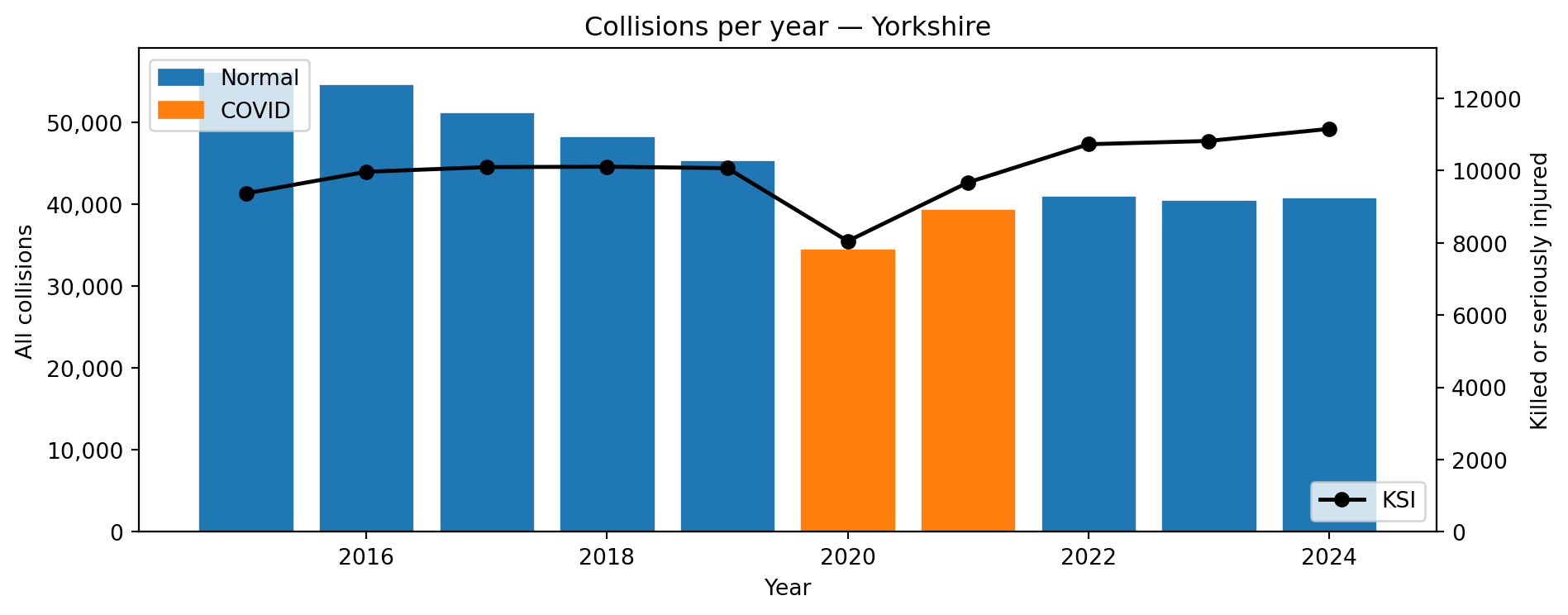
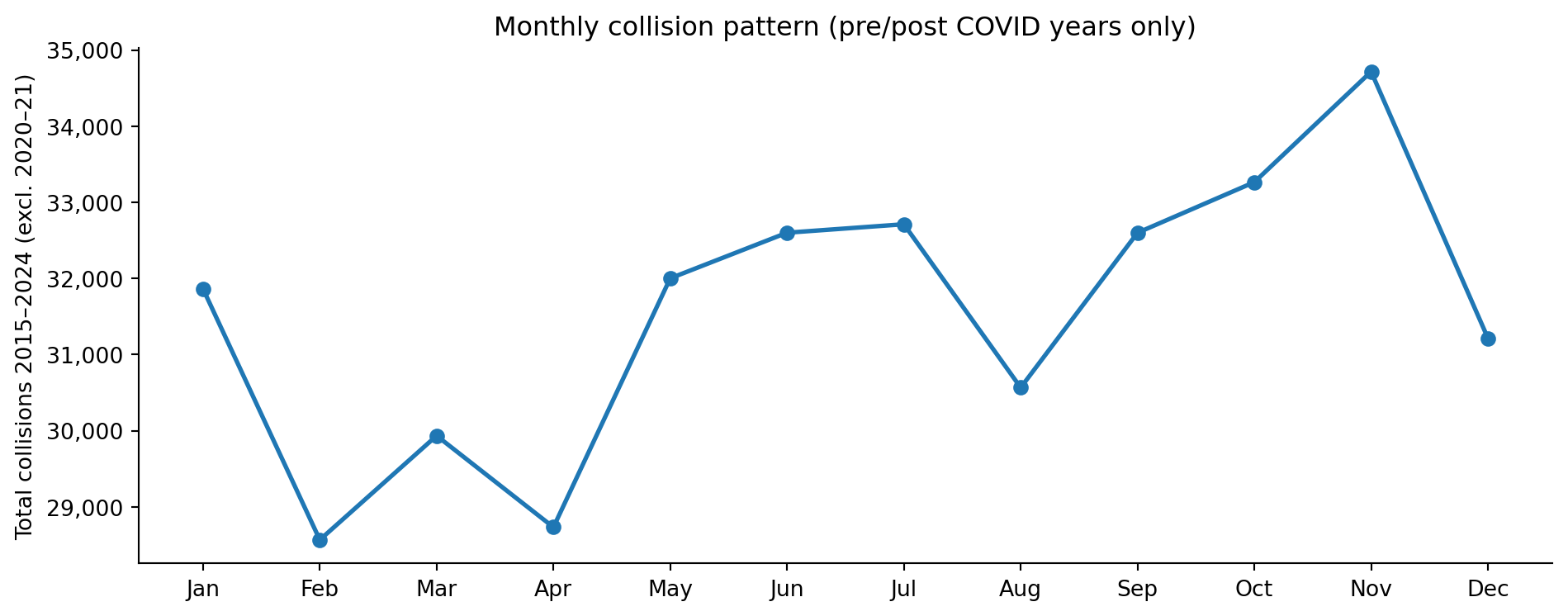
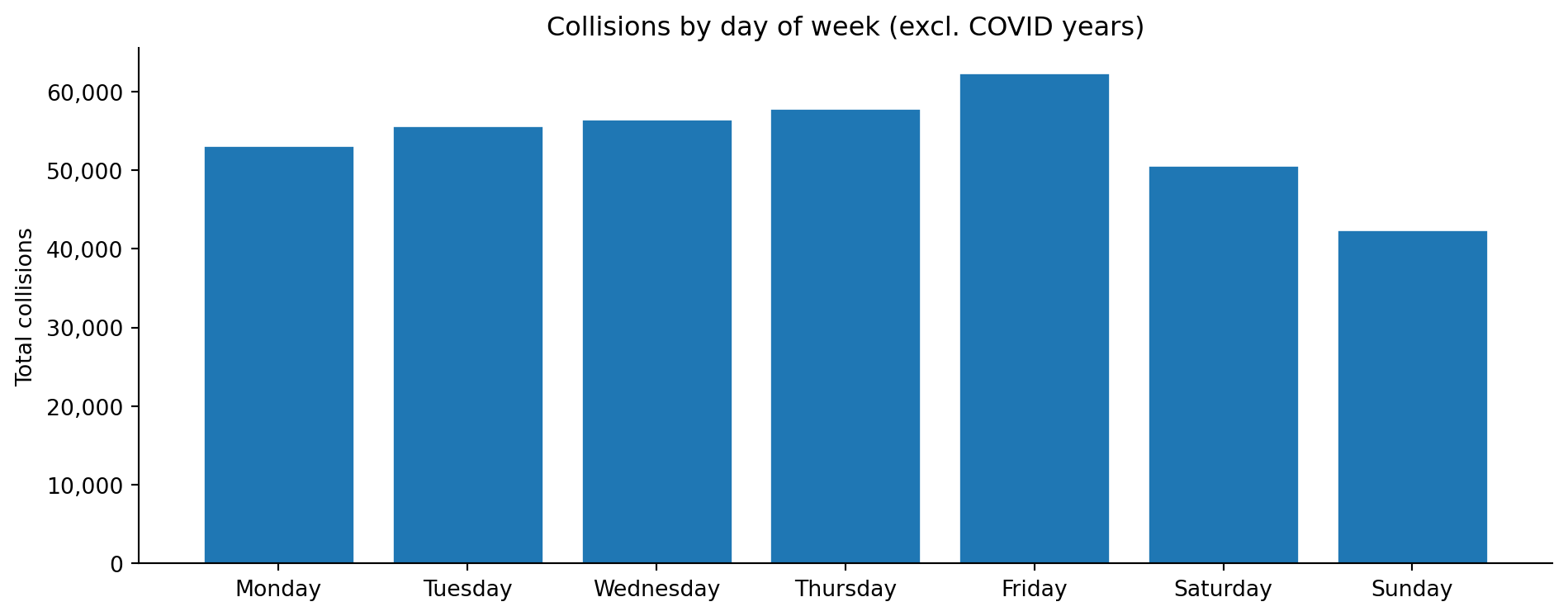
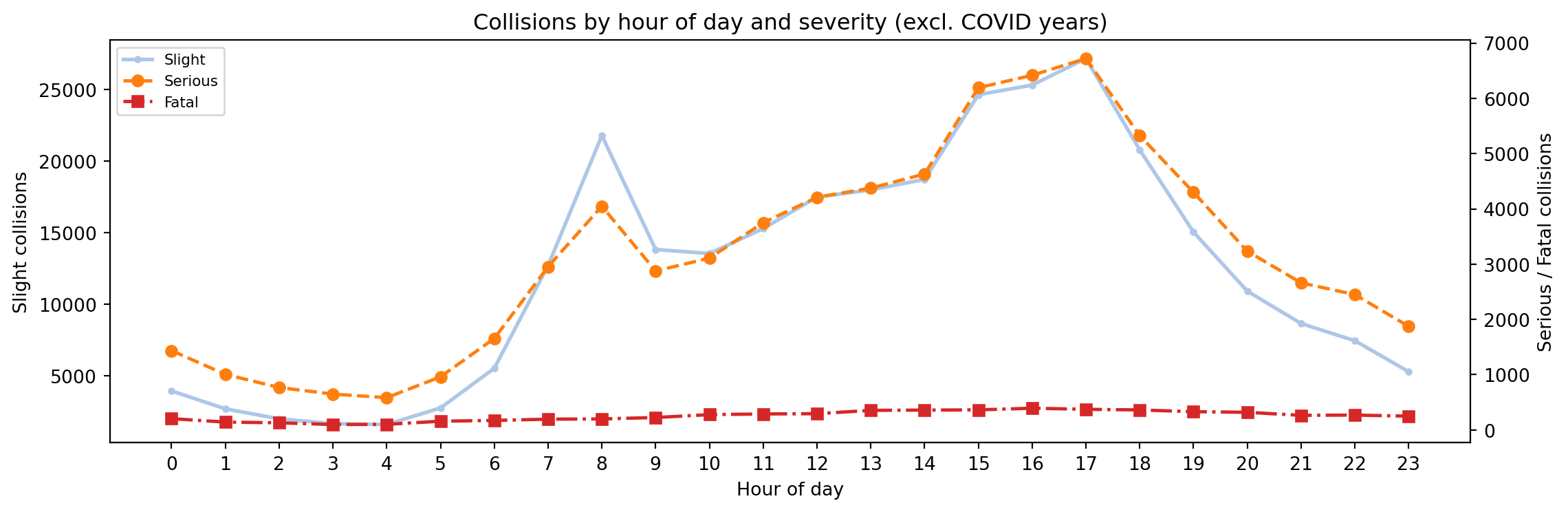
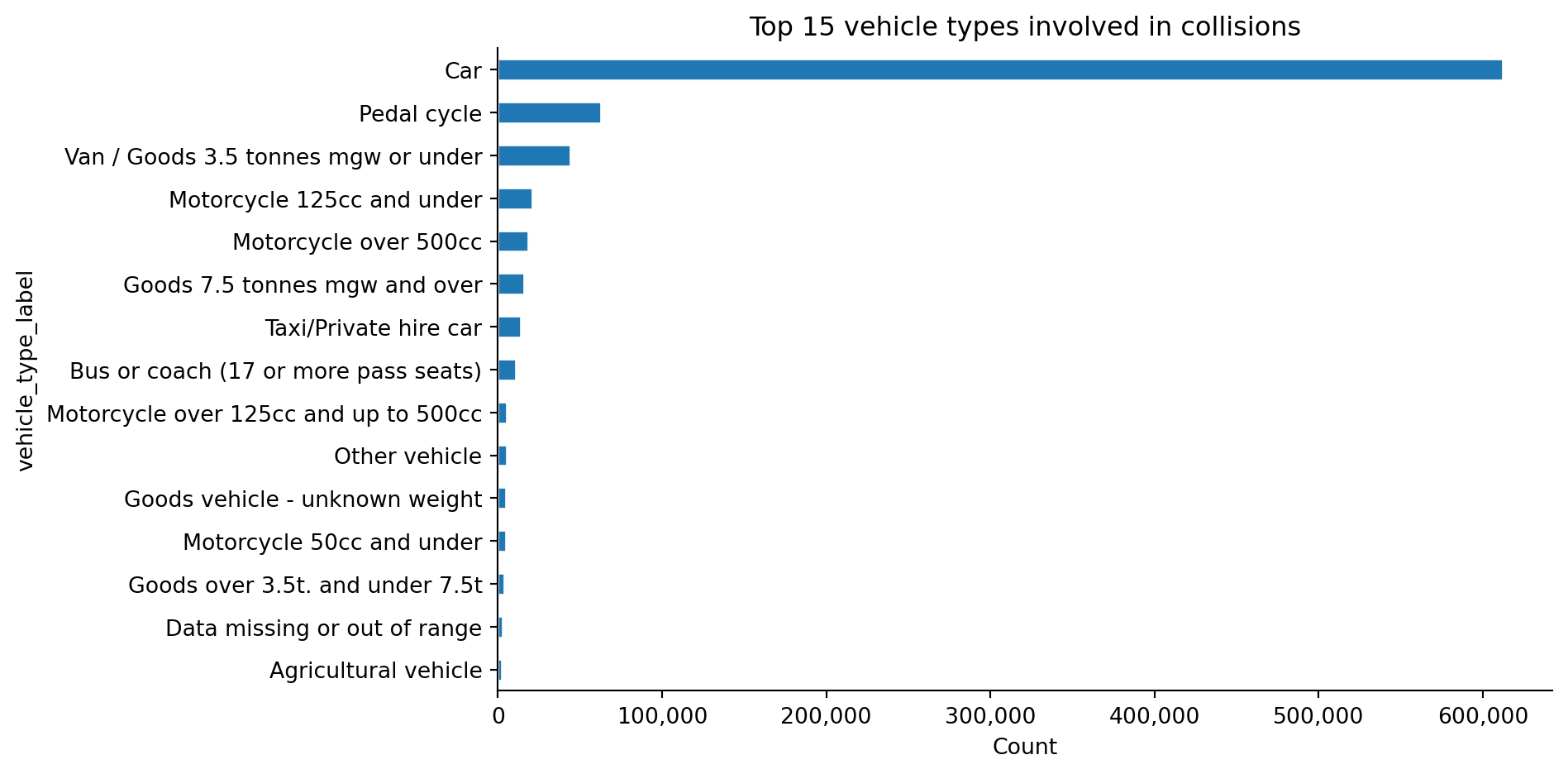
What does the Northern and Central England sample look like over 2015–2024?
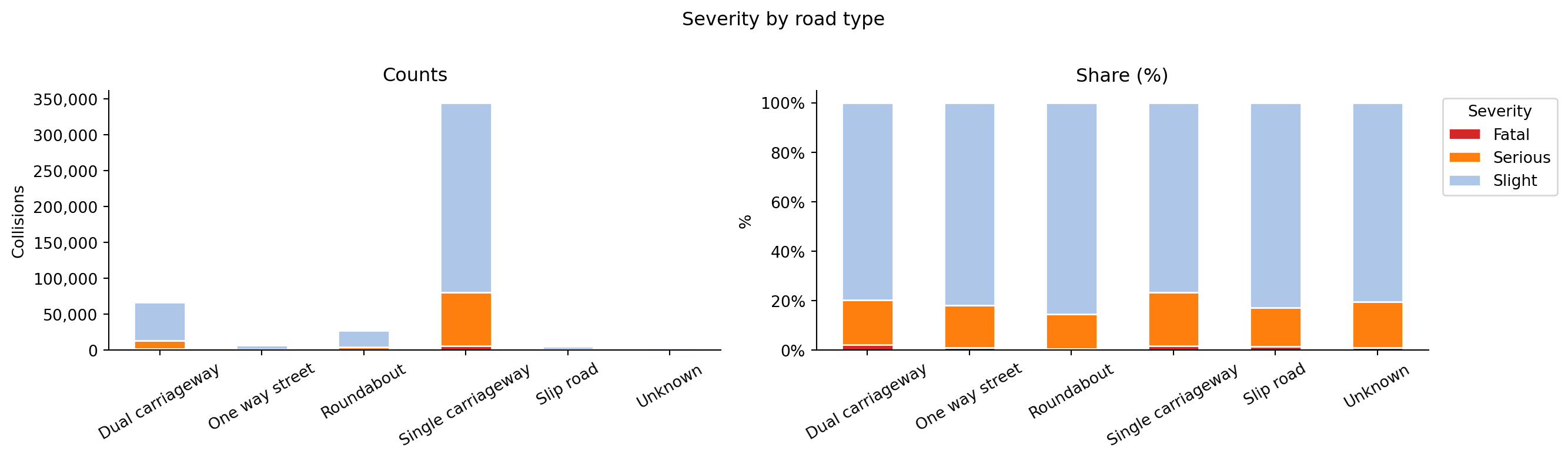
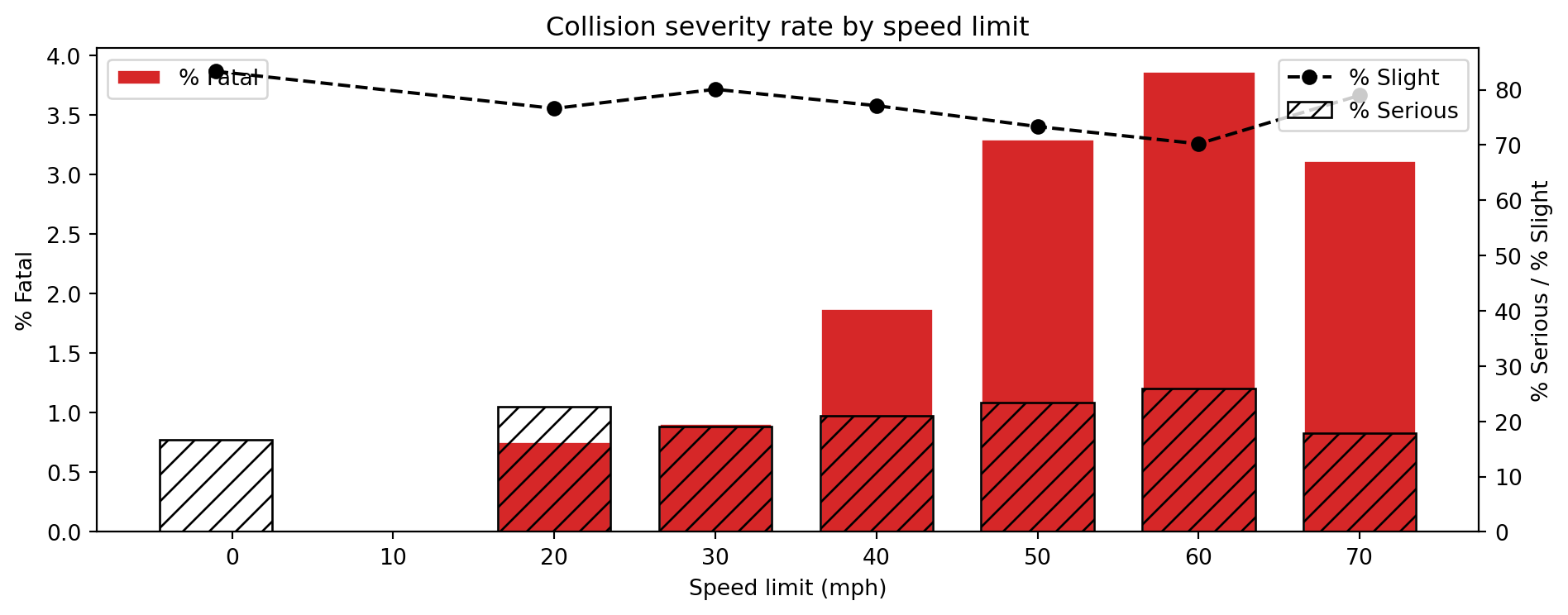
How do severity, road type, time of day, and vehicle mix vary?
How well do the three STATS19 tables link together?
3 What STATS19 is
STATS19 is the official Great Britain road casualty statistics dataset, published by the Department for Transport under the Road Traffic Act 1988.[^1] It records every personal-injury road collision reported to the police, split across three linked tables: collisions, vehicles involved, and casualties.
The dataset has been collected since 1926 using a standardised reporting form completed by police officers attending the scene. Since 2016, many forces have migrated to the CRASH (Collision Reporting And SHaring) system, which replaced paper forms with a structured digital workflow.[^2]
4 How the data is collected
Attending officers record structured fields covering:
Vehicles — type, manoeuvre, point of impact, driver age and sex.
Casualties — severity, class (driver / passenger / pedestrian), age, sex, and whether seat belt or helmet was worn.
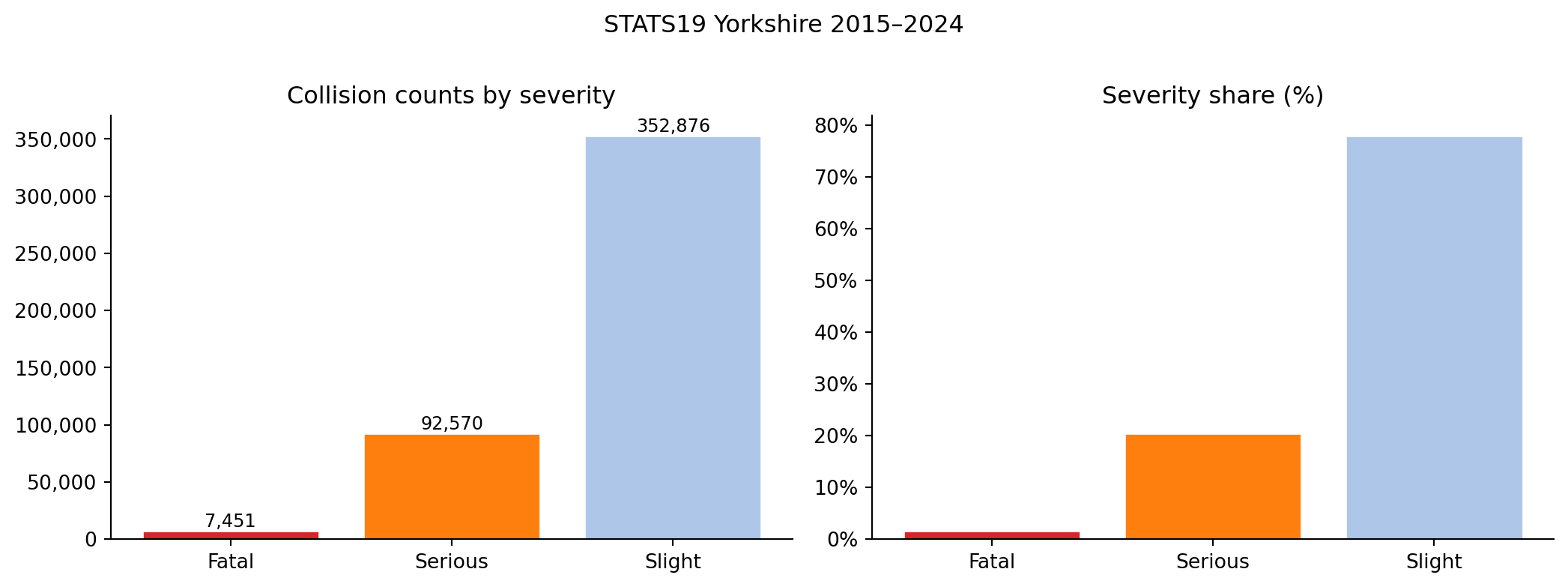
Severity is classified as Fatal (death within 30 days), Serious (injury requiring hospital attention — detained in hospital, fractures, concussion, severe cuts, etc.), or Slight (minor injury — sprains, bruises, shock).[^3]
4.1 Known reporting biases
Several biases in STATS19 are well-documented and matter for how the data is used:
Under-reporting of slight injuries — comparisons with hospital admissions (HES) and NTS self-report data suggest STATS19 captures roughly 60–70% of slight injuries and around 85% of serious injuries. Fatal collisions are near-complete.[^4]
Cyclist and pedestrian collisions are particularly under-reported when no motor vehicle is involved or when injuries are initially judged minor.
Severity re-grading (2016 onwards) — the switch to the CRASH system introduced injury-based severity coding, which increased the recorded count of “serious” injuries relative to pre-2016 methodology. Time-series analysis across the transition requires care.[^5]
Damage-only collisions are not recorded at all — STATS19 is injury-only.
WarningImplication for the model
The model learns collision risk from reported injury collisions. Areas or road types with lower reporting rates (minor rural roads, cyclist infrastructure away from motor traffic) will appear safer than they actually are. The model’s predictions should be interpreted as “expected reported injury collision rate”, not “actual collision risk”.
5 Use in practice
STATS19 is the statutory basis for:
DfT’s annual Reported Road Casualties Great Britain publication.[^6]
Local authority Road Safety Plans and junction-level safety audits.
Academic research into road safety — it underpins most UK-based studies of collision risk, including KSI trend analysis, speed limit evaluations, and vulnerable road user safety.
A common pattern across these uses is to combine STATS19 with traffic exposure data (AADF, WebTRIS) to produce rates rather than raw counts — which is also the approach taken in features.py.
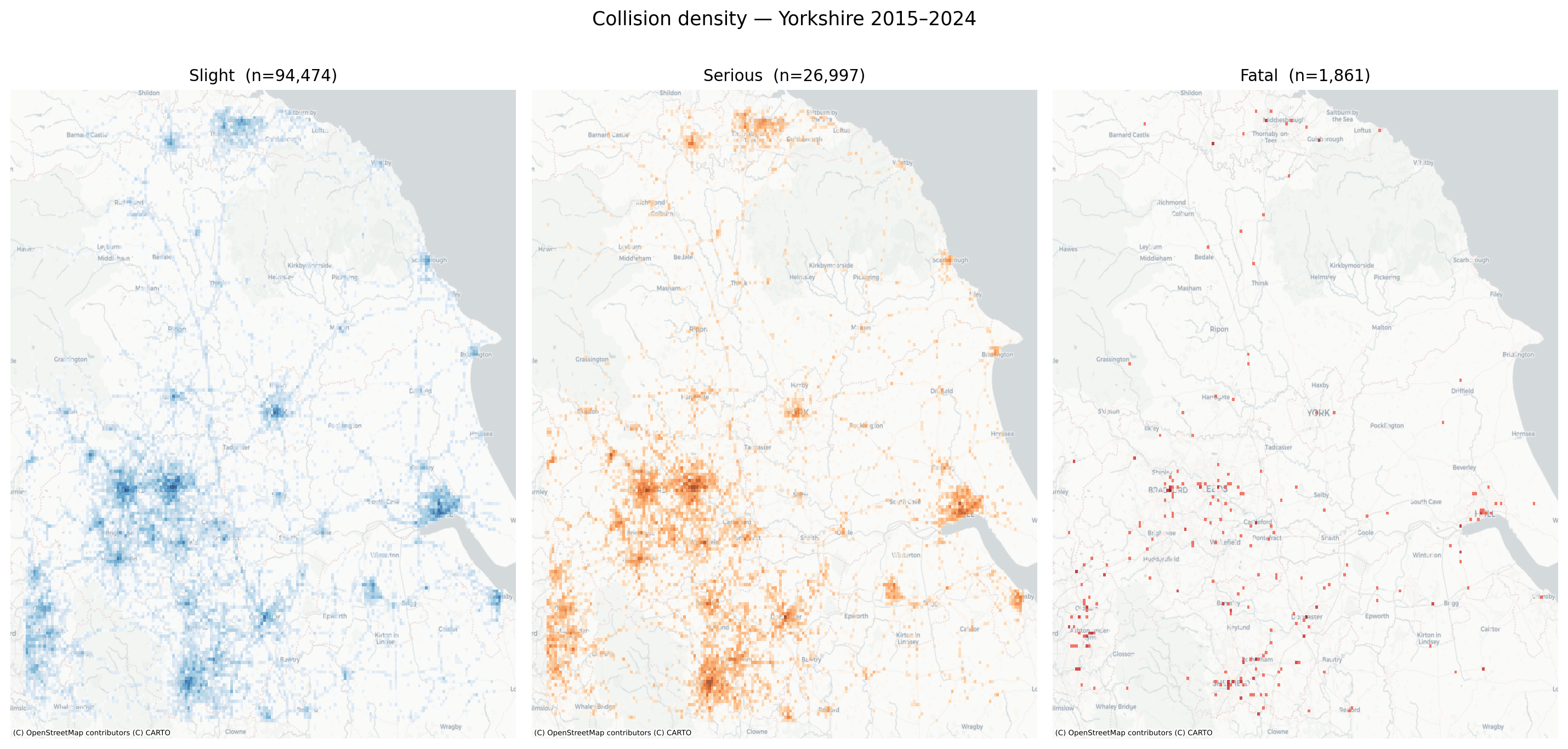
Figure 10: Collision density by severity — Yorkshire 2015–2024 (COVID years included)
16 Join quality
Code
collision_ids =set(collisions["collision_index"])vehicle_ids =set(vehicles["collision_index"])casualty_ids =set(casualties["collision_index"])print("=== Join coverage ===")print(f"Collision IDs : {len(collision_ids):,}")print()print(f"Vehicle records : {len(vehicles):,}")print(f" matched to a collision : {len(vehicle_ids & collision_ids):,}"f" ({100*len(vehicle_ids & collision_ids)/len(vehicle_ids):.1f}%)")print(f" orphaned (no collision match) : {len(vehicle_ids - collision_ids):,}")print()print(f"Casualty records : {len(casualties):,}")print(f" matched to a collision : {len(casualty_ids & collision_ids):,}"f" ({100*len(casualty_ids & collision_ids)/len(casualties):.1f}%)")print(f" orphaned (no collision match) : {len(casualty_ids - collision_ids):,}")print()print(f"Collisions with no vehicles : {len(collision_ids - vehicle_ids):,}")print(f"Collisions with no casualties : {len(collision_ids - casualty_ids):,}")
=== Join coverage ===
Collision IDs : 452,897
Vehicle records : 834,841
matched to a collision : 452,897 (100.0%)
orphaned (no collision match) : 0
Casualty records : 604,874
matched to a collision : 452,897 (74.9%)
orphaned (no collision match) : 0
Collisions with no vehicles : 0
Collisions with no casualties : 0
Code
joined = join_stats19(data)print(f"Joined table : {len(joined):,} rows × {joined.shape[1]} cols")print(f"Casualties : {len(casualties):,}")print(f"Ratio : {len(joined)/len(casualties):.3f} (should be ~1.0)")dup_cols = [c for c in joined.columns if joined.columns.tolist().count(c) >1]print(f"\nDuplicate columns after join: {dup_cols if dup_cols else'none ✓'}")key_cols = ["collision_index", "collision_severity", "vehicle_type","casualty_severity", "casualty_type"]print("\nNull rates on key joined columns:")for col in key_cols:if col in joined.columns: n_null = joined[col].isnull().sum()print(f" {col:35s}: {n_null:,} ({100*n_null/len(joined):.1f}%)")
Joined table : 1,173,293 rows × 104 cols
Casualties : 604,874
Ratio : 1.940 (should be ~1.0)
Duplicate columns after join: none ✓
Null rates on key joined columns:
collision_index : 0 (0.0%)
collision_severity : 0 (0.0%)
vehicle_type : 0 (0.0%)
casualty_severity : 0 (0.0%)
casualty_type : 0 (0.0%)
17 Notes for clean.py
Fill in after running:
Missing lat/lon — rows to drop
Out-of-bbox coordinates — rows to investigate
Speed limit outliers — values to recode as null
HGV vehicle type codes — confirm codes from data guide
COVID flag — years 2020–2021 to be flagged in features.py
Join orphans — vehicle / casualty records unmatched — investigate
18 Known issues
junction_detail had an error corrected in the November 2025 release — ensure you download the latest versions of all files.
2020–2021 volumes are substantially lower due to COVID lockdowns.
A small number of records have missing or implausible lat/lon — these are dropped in clean.py.