Source notes for DfT AADF traffic counts, including count-point coverage, counted-only training data, and traffic exposure estimation.
1 Overview
Annual Average Daily Flow (AADF) data provides measured traffic counts at DfT count points across Great Britain. In this project it is the main source of observed exposure: the dataset that anchors traffic estimation before that exposure is extended to roads without direct counts.
This distinction matters. AADF does not provide complete road-link coverage across the network, so it is not the final exposure layer on its own. Instead, it provides the measured foundation for the wider exposure model.
Important
Unlike WebTRIS, which covers the National Highways network only, AADF extends well beyond motorways and trunk roads. That makes it the project’s main source of measured traffic outside the strategic road network, even though coverage is still incomplete.
2 Role in the pipeline
Supplies measured traffic observations that are joined to OS Open Roads links via spatial nearest-neighbour in join.py.
Anchors the exposure story: observed AADF is used where available, and helps justify traffic estimation where direct counts do not exist.
Contributes vehicle-mix features such as HGV proportion and heavy-vehicle share.
Highlights where exposure is directly measured versus modelled — especially on lower-order roads via the estimation_method column.
In short:
AADF is the measured exposure anchor for the project, but not a complete exposure layer for the full network.
The key thing to keep in mind is that AADF is organised around count points and years, not full road-link coverage. That makes it highly informative where measurements exist, but uneven elsewhere. The page therefore focuses on two questions:
where observed traffic counts exist,
and why those counts are still insufficient on their own for full-network exposure modelling.
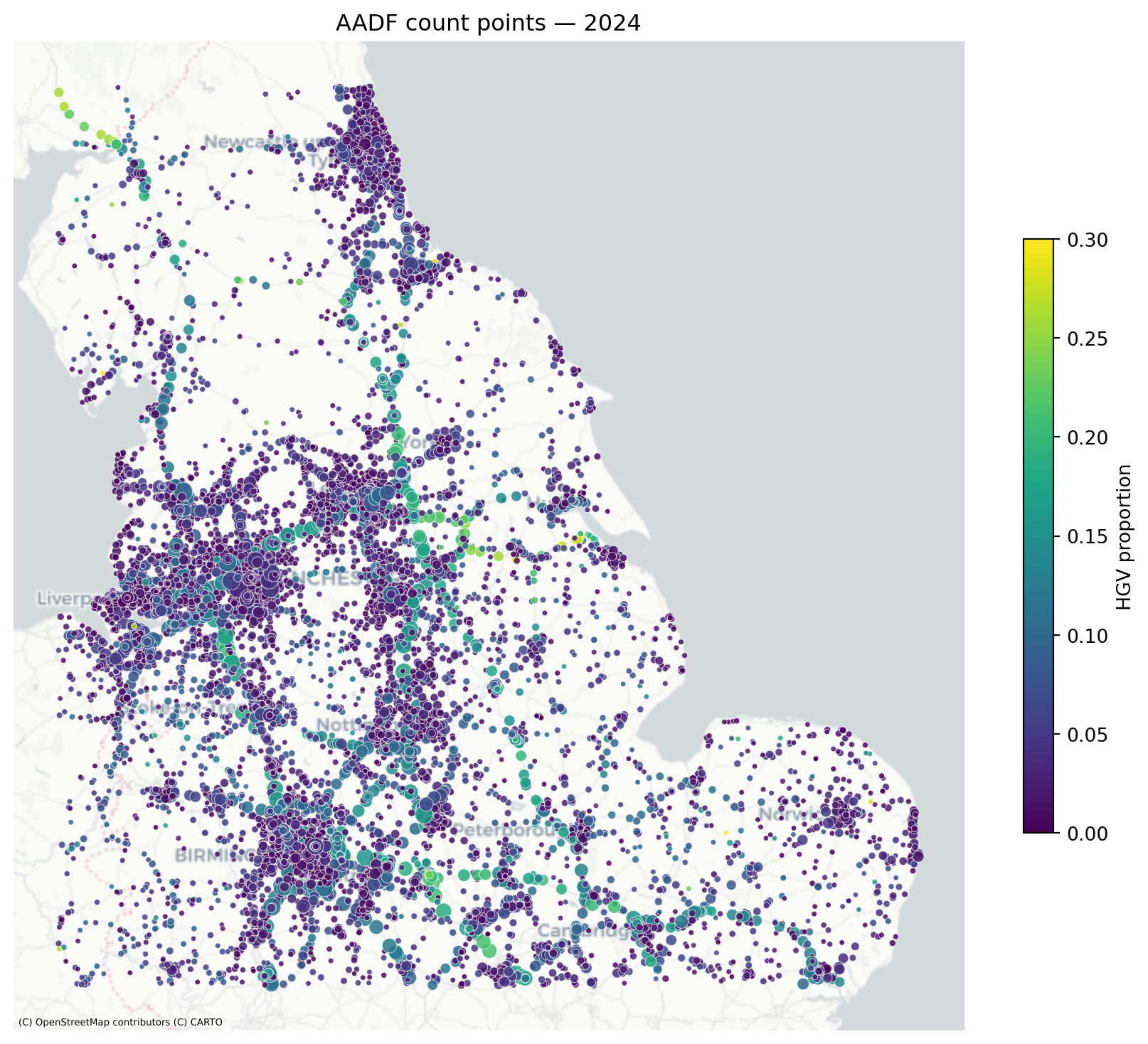
5 Count point coverage
AADF coverage is broader than WebTRIS and extends well beyond the motorway network. Marker size shows traffic volume; colour shows HGV proportion.
This figure is useful less as a map of “all traffic” and more as a map of where the project has measured exposure anchors.
AADF is the strongest directly observed traffic dataset in the pipeline, but it is still incomplete in three important ways:
it is count-point based rather than full road-link coverage,
it is stronger on major roads than local roads,
and only a subset of years may be active in the current modelling workflow.
That is why the project does not stop at joining AADF onto road links. Instead, AADF is used to support the traffic exposure model, which estimates AADT beyond the measured network. ***
10 Known issues and limitations
Bidirectional aggregate — the clean AADF has flows summed across both directions. Directional analysis would require re-running the raw ingest.
Modelled vs counted flow — many minor-road AADFs are modelled from nearby counts. The estimation_method column indicates which. Modelled values are less reliable, particularly for HGV proportion.
Count point drift — count point locations occasionally move between years. The project uses nearest-neighbour spatial join rather than point ID matching to handle this, at the cost of some precision.
Temporal granularity — annual aggregates only. WebTRIS is required for any sub-annual analysis and covers only major roads.
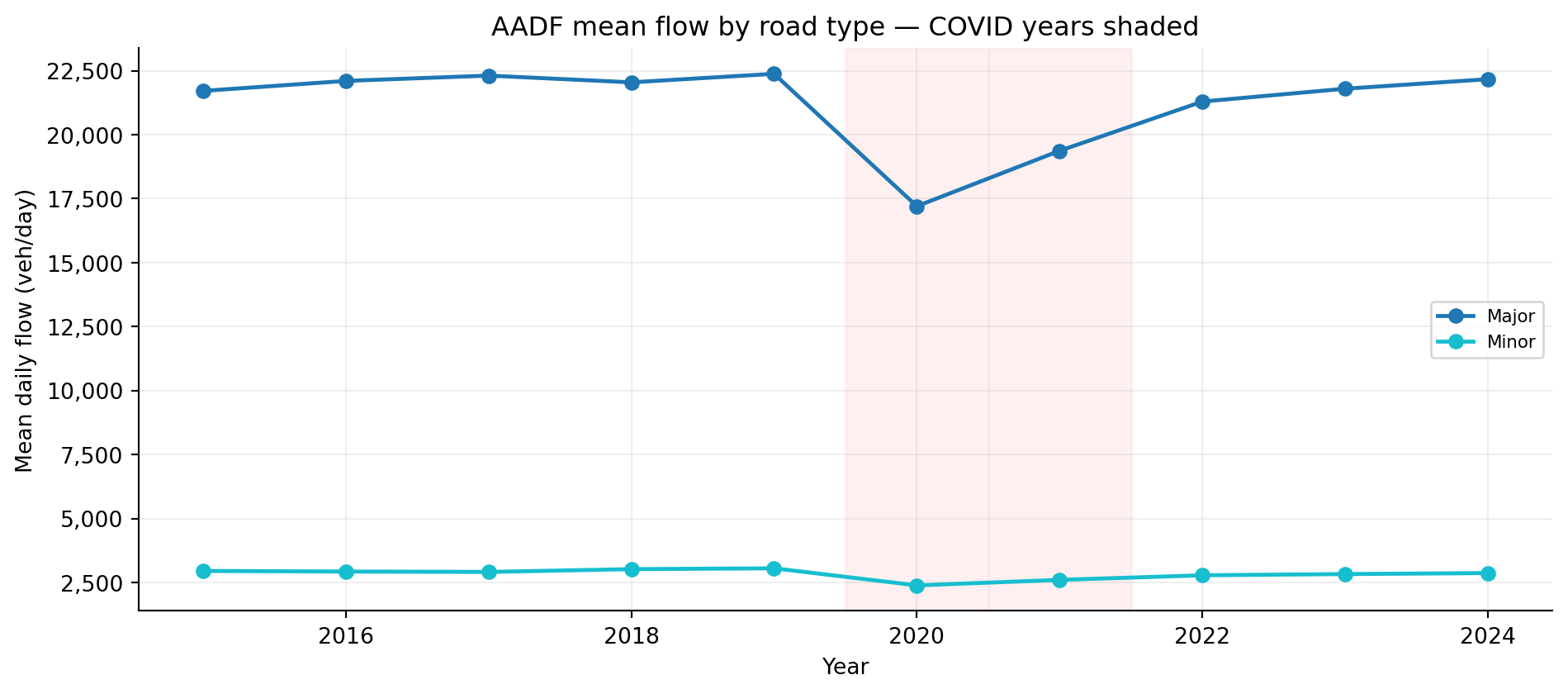
COVID — 2020 flows are substantially suppressed. is_covid flag carried through the pipeline allows exclusion or separate modelling of these years.
11 Next steps
AADF feeds into:
join.py → spatial nearest-neighbour onto OS Open Roads links (2km cap)
features.py → traffic volume and vehicle mix features
collision rate denominator via link_length_km × all_motor_vehicles × 365